신경망 아키텍처
신경망 아키텍처
MLP
다층 퍼셉트론(multilayer perceptron, MLP)은 신경망 아키텍처의 가장 기본적인 형태로서 신경 유닛은 층층이 배열되고 인접한 네트워크 층은 전체가 모두 연결된다

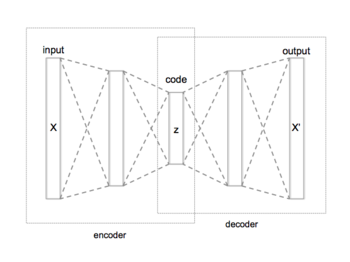
Autoencoder
오토인코더 신경망(Autoencoder)의 목표값은 입력값과 동일하게 설정된다. 은닉층당 유닛 수가 점진적으로 증가하기 전에 특정 시점까지 점진적으로 감소하고, 최종 층의 차원은 입력 차원과 동일하다. 은닉층의 앞쪽 절반을 인코더(encoder) 뒤쪽 절반을 디코더(decoder)라고 한다.
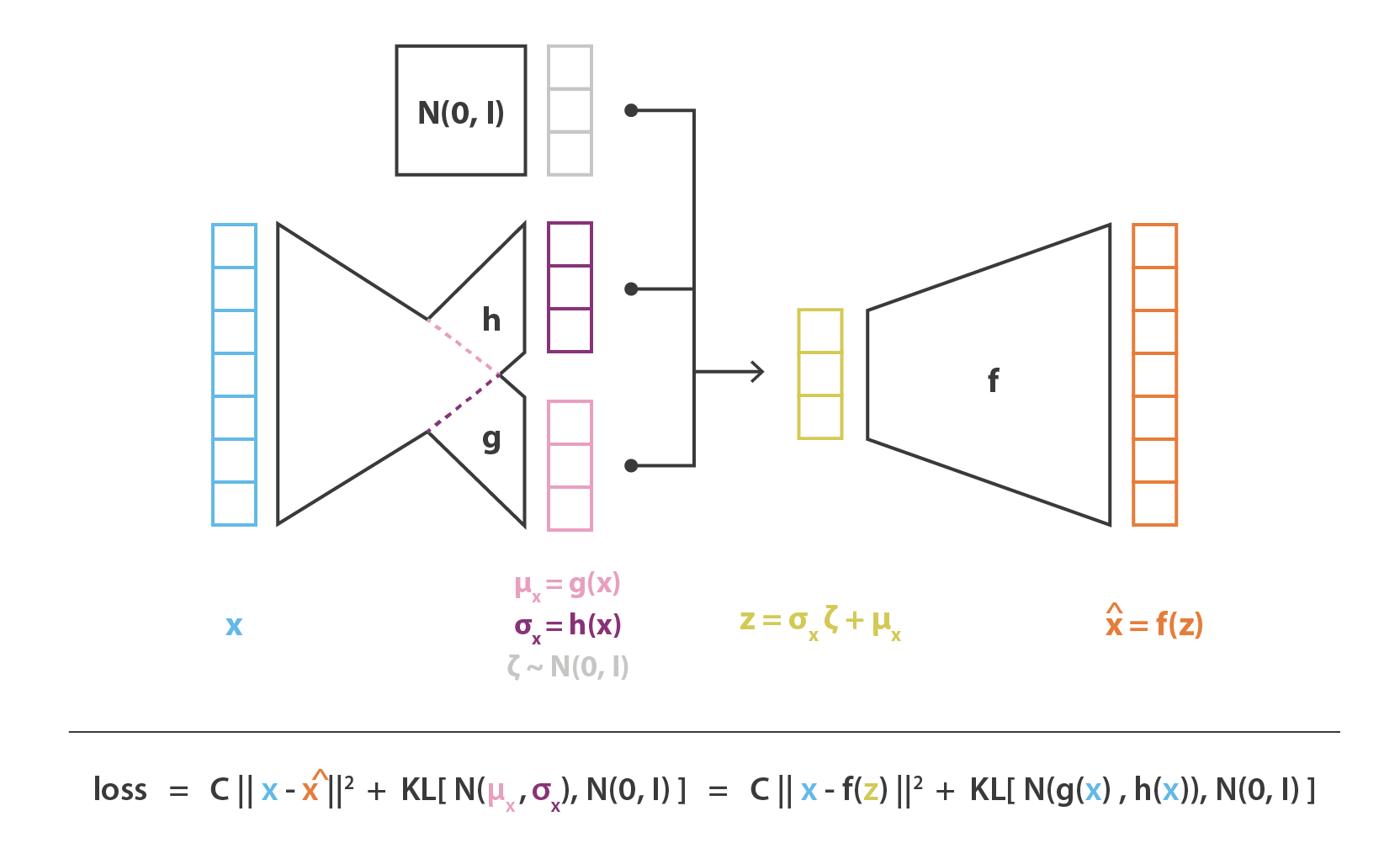
VAEs
변분 오토인코더(variational autoencoders, VAEs)의 디코더 부분은 오토 인코더와 동일하고 인코더 부분에서 확률층(noise)를 추가하여 여러 샘플을 얻어서 최대 가능도로 손실함수를 도출한다
GAN
적대적 신경망(Generatice Adversarial Networks, GAN)에는 생성기 신경망과 판별기 신경망이 있다. 생성기 네트워크는 임의의 소음을 입력받아 데이터 샘플을 생성하려고 시도한다. 판별기 네트워크는 생성된 데이터를 실제 데이터와 비교하고 생성된 데이터가 가짜인지 아닌지에 대한 이진 분류 문제를 시그모이드 출력 활성화를 사용해 해결한다.

LeNet
1998년에 설계한 7단계 합성곱 네트워크로, 숫자 분류에 사용된다.

AlexNet
2012년 ILSVRC우승팀의 아키텍처. LeNet과 매우 유사한 아키텍처를 가지고 있지만, 층당 필터가 더 많고 깊다. 또한 항상 대체된 합성곱 풀링 대신 스택 합성곱을 사용한다. 작은 합성곱의 스택은 합성곱층의 하나로 된 커다란 수용 영역보다 낫다. 더 많은 비선형성과 더 적은 파라미터를 도입하기 때문이다.

ZFNet
2013년 ILSVRC 우승팀의 아키텍처. AlexNet을 향상시키기 위해 아키텍처 하이퍼 파라미터를 조정했는데, 특히 중간 합성곱층의 크기를 확장하고 첫 번째 층의 스트라이드와 필터 크기를 작게 함으로써 11x11 스트라이드 4인 AlexNet이 7x7 스트라이드 2인 ZFNet으로 변경됐다. 이렇게 시도한 이유는 첫 번째 합성곱층의 필터 크기가 작으면 많은 원본 픽셀 정보를 유지하는 데 도움이 되기 때문이다. 또한 AlexNet은 1,500만 개의 이미지에 대한 훈련을 받았지만, ZFNet은 130만 개의 이미지에 대해서만 훈련을 받았다

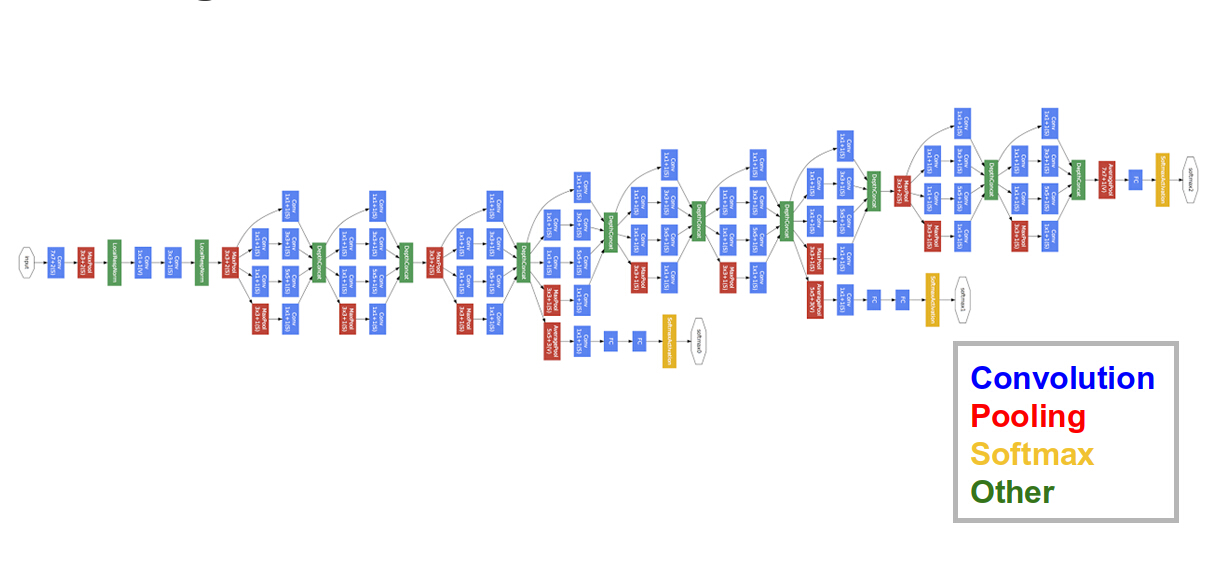
GoogLeNet
2014년 ILSVRC 우승팀의 아키텍처. GoogLeNet은 CNN을 사용해 인셉션층(Inception layer)이라는 새로운 아키텍처의 구성요소를 도입했다. 인셉션 층은 더 큰 합성곱을 사용하고 더 작은 정보의 이미지에도 정밀한 해상도를 유지할 수 있기 때문에 적용되었다.
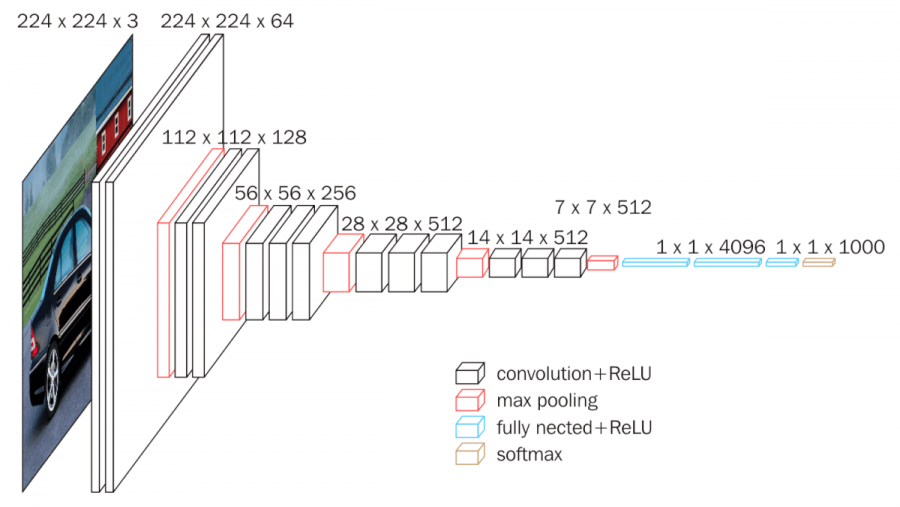
VGG
2014년 ILSVRC 준우승팀의 아키텍처. VGG 네트워크는 단순함이 그 특징인데, 3x3 합성곱층만 사용해 쌓아올렸다. 부피를 줄이는 것은 Max Pooling으로 처리된다. 마지막에는 4,096개의 노드가 있는 두 개의 전체가 연결된 층에 소프트맥스 층이 이어진다. 입력에 대한 전처리는 훈련 세트에서 계산된 평균 RGB 값을 각 픽셀에서 빼는 것이다. 풀링은 일부 합성곱층을 따르는 Max Pooling에 의해 이루어 진다. 모든 합성곱층 다음에 Max Pooling이 이어지는 것은 아니다. Max Pooling은 스트라이드가 2인 2x2 픽셀 윈도에서 이루어진다. ReLU 활성화는 각각의 은닉층에서 사용된다. 필터의 수는 대부분 VGG 변형에서 깊이에 따라 증가한다. 16층은 VGG-16, 19층은 VGG-19.
ResNet
2015년 ILSVRC 우승팀의 아키텍처. 잔차 신경망(Residual Neural Network: ResNet)은 연결 건너뛰기와 배치 정규화를 사용하는 새로운 CNN 아키텍처로서 이를 통해 VGG 네트워크보다 복잡성이 낮은데도 152층의 신경망을 훈련할 수 있었다.
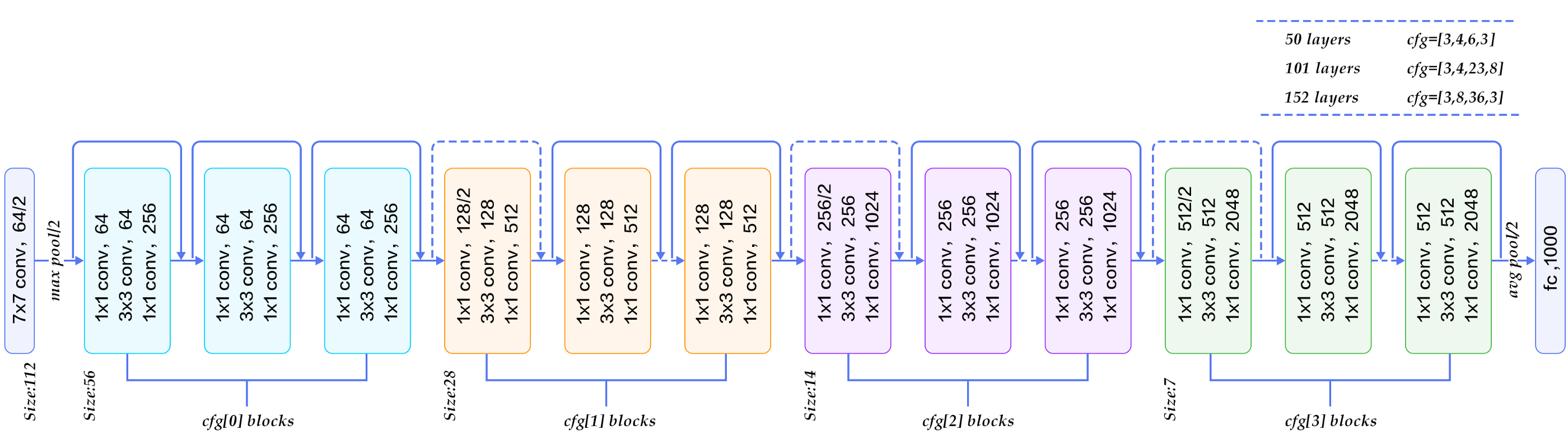
CapsNet
캡슐 네트워크(CapsNet)는 CNN의 스칼라 출력 함수 감지기를 벡터 출력 캡슐로 대체한다. 또 라우팅별로 Max Pooling을 사용한다
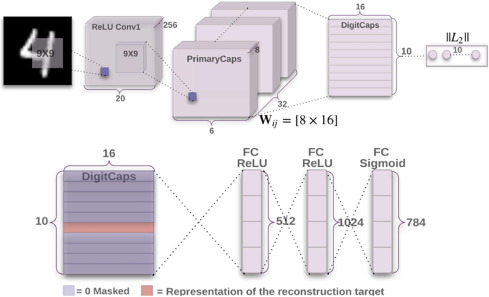
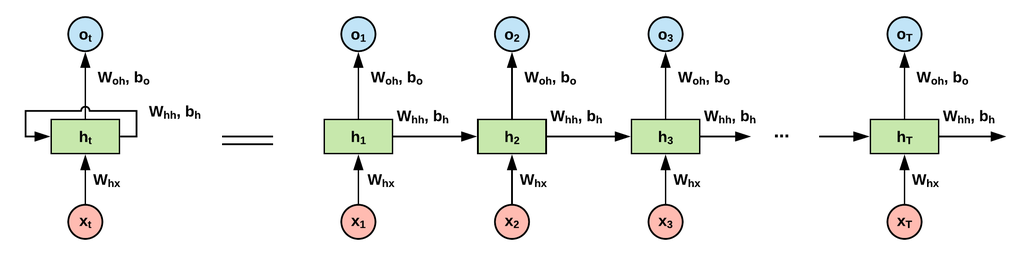
RNN
순환 신경망(recurrent neural Network, RNN)은 시퀀스를 처리하는 데 특화돼 있다. 예를 들어, 주어진 최근 시퀀스로부터 다음 시퀀스에 있는 용어를 예측하거나 한 언어에서 다른 언어로 단어의 시퀀스를 번역하려는 경우, 시퀀스 모델링을 할 필요가 있다. RNN은 아키텍처에 피드백 루프가 있다는 점에서 전방 전달 네트워크와 구별된다. 종종 RNN에는 메모리가 있다고 한다. RNN은 시간이 지남에 따라 순서대로 이전 내용을 잃기 시작한다.
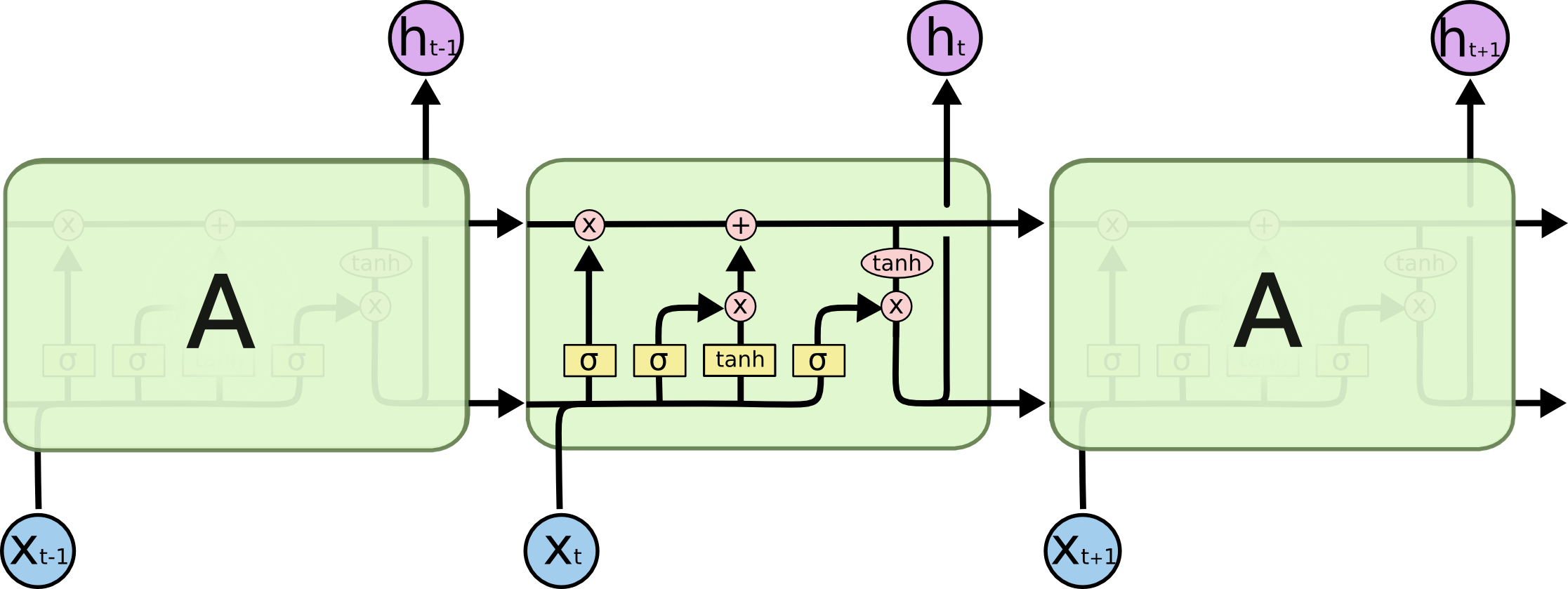
LSTM
LSTM은 일반적으로 입력, 출력 및 망각 게이트를 포함해 3개 또는 4개의 게이트로 구성된다. 입력 게이트는 일반적으로 들어오는 신호 또는 입력을 수용하거나 거부해 메모리 셀 상태를 변경한다. 출력 게이트는 일반적으로 필요에 따라 다른 뉴런에 값을 전달한다. 망각 게이트는 메모리 셀의 자기 반복 연결을 제어해 필요에 따라 이전 상태를 기억하거나 잊어버린다.
NMT
신경망 기반 기계 번역(Neural Machine Translation, NMT) 시스템은 일반적으로 인코더와 디코더 두 모듈로 구성된다. 먼저 인코더로 소스 문장을 읽고 생각 벡터를 만든다. 이 벡터는 문장의 의미를 나타내는 숫자의 시퀀스로 구성된다. 디코더는 문장 벡터를 처리해 다른 타깃 언어로 번역을 출력한다. 이를 인코더-디코더 아키텍처라고 한다.
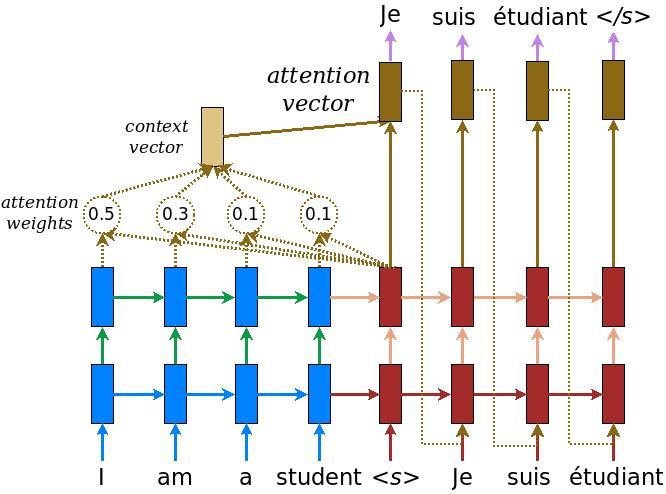
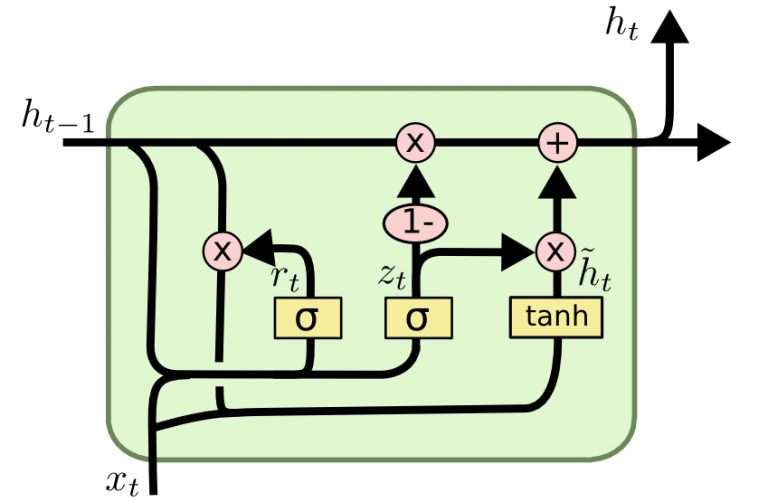
GRU
게이트 순환 유닛(Gated Recurrent Units, GRU)은 LSTM과 관련이 있다. 둘 다 게이트 정보의 다른 방법을 사용해 기울기 소멸 문제를 방지하고 장기 메모리에 저장한다. GRU에는 두 개의 게이트가 있는데, 리셋 게이트 r과 업데이트 게이트 z다 . 리셋 게이트는 새 입력을 어떻게 이전의 은닉상태와 결합할 것인지 결정하고 업데이트 게이트는 유지할 이전 상태 정보의 양을 정의한다.
출처: 딥러닝 전이학습, “위키북스”
댓글남기기