
생성적 적대 신경망 소개
생성적 적대 신경망(generative adversarial networks, GAN)
2014년 Ian Goodfellow 등의 논문에서 처음 소개된 심층 신경망 아키텍처
GAN 이란 무엇인가?
GAN은 생성기 신경망과 판별기 신경망이라고 하는 두 가지 신경망으로 구성된 심층 신경망 아키텍처이다. 예를들어 생성기 신경망은 위조 지폐를 생성하여 판별기 신경망을 속이는 것을 목표로 하고, 판별기 신경망은 위조지폐를 찾아내는 것을 목표로 한다. 위조지폐가 정교해지면 판별성능이 떨어지고 반복학습을 통해 판별기가 발전하고, 판별기가 위조지폐를 잘 찾아내면 생성기가 반복학습을 통해 발전하는 원리로 적대적으로 경쟁하며 발전시킨다.
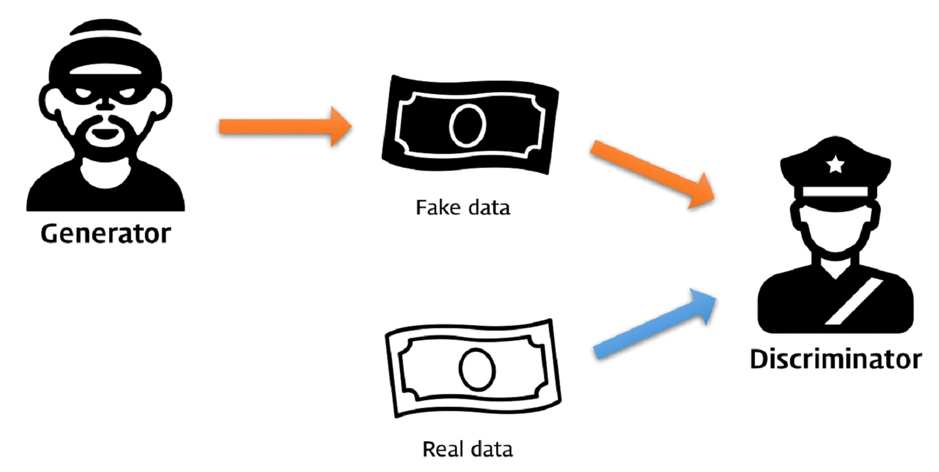
생성기 신경망(generator network): 기존 데이터를 사용해 신규 데이터를 생성해 낸다
(예: 이미지, 비디오, 오디오 또는 텍스트 등)
판별기 신경망(discriminator network): 진짜 데이터와 신규 데이터를 구분하는 신경망으로 다중 분류나 이진 분류 모두 가능하다
GAN 훈련 과정
- 생성기가 진짜 데이터를 통해 가짜 데이터를 생성한다
- 판별기는 가짜 데이터를 구분해 낸다
- 생성기는 이와 같은 과정을 반복하면서 진짜에 가까운 데이터를 생성하고, 판별기는 기준(criterion)을 조정하면서 구분한다
- 생성기와 판별기는 각 반복과정에서 성공적인 변경사항을 피드백 하면서 훈련한다
- 궁극적으로, 판별기는 진짜 데이터와 가짜 데이터를 구분하지 못하게 생성기를 훈련시키게 된다
GAN의 아키텍처
생성기와 판별기 모두 인공 신경망(artificial neural network, ANN), 합성곱 신경망(convolutional neural network, CNN), 재귀 신경망(recurrent neural network, RNN) 또는 장단기 기억 신경망(long short term memory, LSTM) 을 신경망으로 사용할 수 있으며, 판별기 끝부분에 있는 분류기가 완전 연결형태여야 한다
- 생성기 아키텍처 예
| 계층# | 계층 이름 | 구성 |
|---|---|---|
| 1 | Input layer | input_shape=(batch_size, 100), output_shape=(batch_size, 100) |
| 2 | dense layer | neurons=500, input_shape=(batch_size, 100), output_shape=(batch_size, 500) |
| 3 | dense layer | neurons=500, input_shape=(batch_size, 500), output_shape=(batch_size, 500) |
| 4 | dense layer | neurons=784, input_shape=(batch_size, 500), output_shape=(batch_size, 784) |
| 5 | reshape layer | input_shape=(batch_size, 784), output_shape=(batch_size, 28, 28) |
- 판별기 아키텍처 예
| 계층# | 계층 이름 | 구성 |
|---|---|---|
| 1 | flatten layer | input_shape=(batch_size, 28, 28), output_shape=(batch_size, 784) |
| 2 | dense layer | neurons=784, input_shape=(batch_size, 784), output_shape=(batch_size, 500) |
| 3 | dense layer | neurons=500, input_shape=(batch_size, 500), output_shape=(batch_size, 500) |
| 4 | dense layer | neurons=1, input_shape=(batch_size, 500), output_shape=(batch_size, 1) |
GAN과 관련된 주요 개념
- 쿨백-라이블러 발산
쿨백-라이블러 발산(Kullback-Leibler divergence, KL 발산)은 상대 엔트로피(relative entropy)로도 알려져 있는데, 두가지 확률 분포 간의 유사도를 알아내는데 사용하는 방법이다. 하나의 확률분포 p(x)가 두번째 기대 확률 분포 q(x)와 어떻게 다른지 측정한다. p(x)와 q(x)가 같을때 KL 발산은 최소가 되고, KL 발산은 비대칭 특성이 있기 때문에 두 확률 분포 사이의 거리를 측정할때는 사용할 수 없다
- 옌센-섀넌 발산
옌센-섀넌 발산(Jensen-Shannon divergence, JS 발산)은 정보 반경(information radius, IRaD)나 평균에 대한 총 발산(total divergence to the average)라고도 하며, 역시 두가지 확률 분포 간의 유사도(similarity)를 알아내는데 사용하는 방법이다. KL 발산을 바탕으로 만들어 졌지만 JS 발산은 대칭적이며, 두 확률 분포 사이의 거리를 측정하는 데 사용할 수 있다
- 내시 균형
내시 균형(Nash equilibrium)이란 게임 이론에서 특정 상태를 묘사할 때 쓰는 용어이다. 각 플레이어는 최선의 전략을 고르는 비협력 게임에서, 모든 플레이어들의 결정을 바탕으로 자신들만의최고 전략을 선택하게 되지만, 게임 도중에 이 지점에 도달하면 전략을 변화시킴으로써 얻을 수 있는 이익이 없게 된다.
- 목적 함수 생성기와 판별기 모두 자체 목적 함수들이 훈련을 하는 동안 판별기는 총 출력을 최대화 하고, 생성기는 최소화하게 되어 GAN에 대한 최종 목적함수가 균형을 잡게 되고, 이때 모델이 수렴했다고 한다. 이 균형이 내시 균형이다.
- 인셉션 점수
인셉션 점수(inception score, IS)는 GAN에서 가장 널리 사용하는 점수 알고리즘이다. 사전 훈련 인셉션 V3 신경망을 사용해 생성된 이미지와 진짜 이미지의 특징을 추출한다. 모델에서 생성된 영상 N개를 표본 추출한뒤 KL 발산 및 예상되는 인셉션을 계산하고 나온 결과값에 지수를 취하면 인셉션 점수를 알 수 있다. 인셉션 점수가 높다는 것은 모델 품질이 좋다는 말이다.
- 프레셰 인셉션 거리
프레세 인셉션 거리(Freshlet inception distance, FID)는 인셉션 점수의 다양한 단점을 극복하기 위한 방법이다. FID 점수는 인셉션 신경망을 사용하여 인셉션 신경망의 중간 계층에서 특징 지도를 추출한다. 그런 다음, 특징 지도의 분포를 학습하는 다변량 가우스 분포를 모델링한다. 수식을 계산하여 나온 점수가 낮을 수록 모델이 더 좋아지고 더 다양한 이미지를 고품질로 생성할 수 있다. 인셉션 점수보다 잡음에 강하고 이미지의 다양성을 쉽게 측정할 수 있다.
GAN의 장단점
장점
- GAN은 비지도학습 방식이다. 레이블 없이 데이터 훈련을 할 수 있다
- GAN은 데이터를 생성한다. 실제와 유사한 데이터를 늘릴 수 있다
- GAN은 데이터의 밀도 분포를 학습한다. 데이터의 내부 표현을 학습하여 다양한 문제에 응용할 수 있다
- 훈련된 판별기는 일종의 분류기이다. 판별기 신경망은 물체를 분류하는데 활용할 수 있다
단점
- 최빈값 붕괴(mode collapse): 생성기 신경망이 표본을 다양하게 생성하지 못하는 문제이다
- 해결법: 다양한 최빈값을 지니게 여러 가지 모델(GAN)을 훈련, 다양한 데이터 표본으로 훈련
- 경사 소멸 (vanishing gradients): 경사도가 너무 작아져서 초기 계층의 가중치가 바뀌지 않아서 훈련이 중단되는 문제
- 해결법: ReLU, LeakyReLU 및 PReLU등의 활성함수를 활용하거나 배치 정규화(batch nomalization을 사용
- 내부 공변량 변화(internal covariate shift): 입력 분포가 변경될 때 새로운 분포에 적응하기 위해 처리 과정이 느려져 전역 최솟값으로 수렴하는데 오랜 시간이 걸리는 문제
- 해결법: 배치 정규화 기법으로 해결
GAN 훈련 시의 안정성 문제 해결하기
Improved Techniques for Training GANs
- 특징 정합 특징 정합(feature matching)은 목적함수가 수렴되는 것을 개선하기 위해 제안된 기술이다. 신경망은 판별기에게 이진 레이블을 제공하지 않게 하고 자체 신경망의 중간 계층에서 추출한 입력 데이터의 활성치나 특징 지도를 제공하여 진짜 데이터의 중요한 통계량을 학습하여 더 나은 결과를 얻을 수 있다. 하지만 수렴을 보장하지는 않는다
- 미니배치 판별 최빈값 붕괴(mode collapse)문제가 생겼을 때 사용하는 방법이다. 표본에 대한 특징 지도들을 추출하고 나서 이것들에 텐서를 곱한다. 그런 후에 각 행 사이의 L1 거리를 계산한다. 그리고 나서 특정 사례에 대한 모든 거리의 합계를 계산한다. 그런 다음에 접합하여 신경망의 다음 계층으로 공급한다
- 역사적 평균 역사적 평균(historical averaging)이란 과거 파라미터의 평균을 취하여 이를 생성기 신경망 및 판별기 신경망의 각 비용 함수에 추가하는 접근 방식이다. 이를 통해 훈련 안정성을 향상시킬 수 있다
- 단측 레이블 평활화 단측 레이블 평활화(onesided label smoothing)는 판별기 신경망에 평활화된 레이블을 제공하여 0과 1 대신에 0.2, 0.7등의 소숫점을 가질 수 있게 하는 방법이다.
- 배치 정규화 배치 정규화(batch normalization)는 평균 또는 단위 분산이 없도록 특징 벡터를 정규화하는 기술이다. 이것은 학습을 안정시키고 부족한 가중치 초기화 문제를 다루기 위해 사용된다. 배치 정규화는 신경망의 은닉계층에 적용하는 전처리 단계로서 내부 공변량 변화를 줄이는 데 도움이 된다
- 사례 정규화 해당 특징 지도의 정보만 활용하여 각 특징 지도를 정규화 한다.
그 밖의 다양한 GAN
- DCGAN: 최초로 GAN에 합성곱 신경망을 두었다
- StackGAN: 텍스트 대 이미지 합성을 탐구에 사용되는 GAN 알고리즘
- CycleGAN: 사진을 그림으로 변환하거나 그 반대로 변환하거나, 날씨등도 바꿀수 있는 GAN 알고리즘
- 3D-GAN: 객체의 3D 모델에 대해 교육을 받으면 다른 객체의 새로운 3D 모델을 생성할 수 있다
- Age-cGAN: cGAN을 이용한 얼굴 노화에 대해 사용할 수 있다
- pix2pix: 건물 레이블을 사용해 건물 사진으로 변환하거나, 흑백 이미지를 컬러로 변환하는 등에 사용할 수 있다
출처: 실전! GAN 프로젝트, “위키북스”
댓글남기기